I know a few fellow devs who still use Visual Studio or Rider as their IDE for Typescript. If you’re one of them, this is going to be a little rant on you all 😄
In this short article, I will give you my 5 reasons why the backend code editor might not be the best IDE for frontend development 😉
NOTE: calling this post a “rant” is obviously humorous 😉 This article is my own opinion, not a hate on anyone using different IDEs than I do.
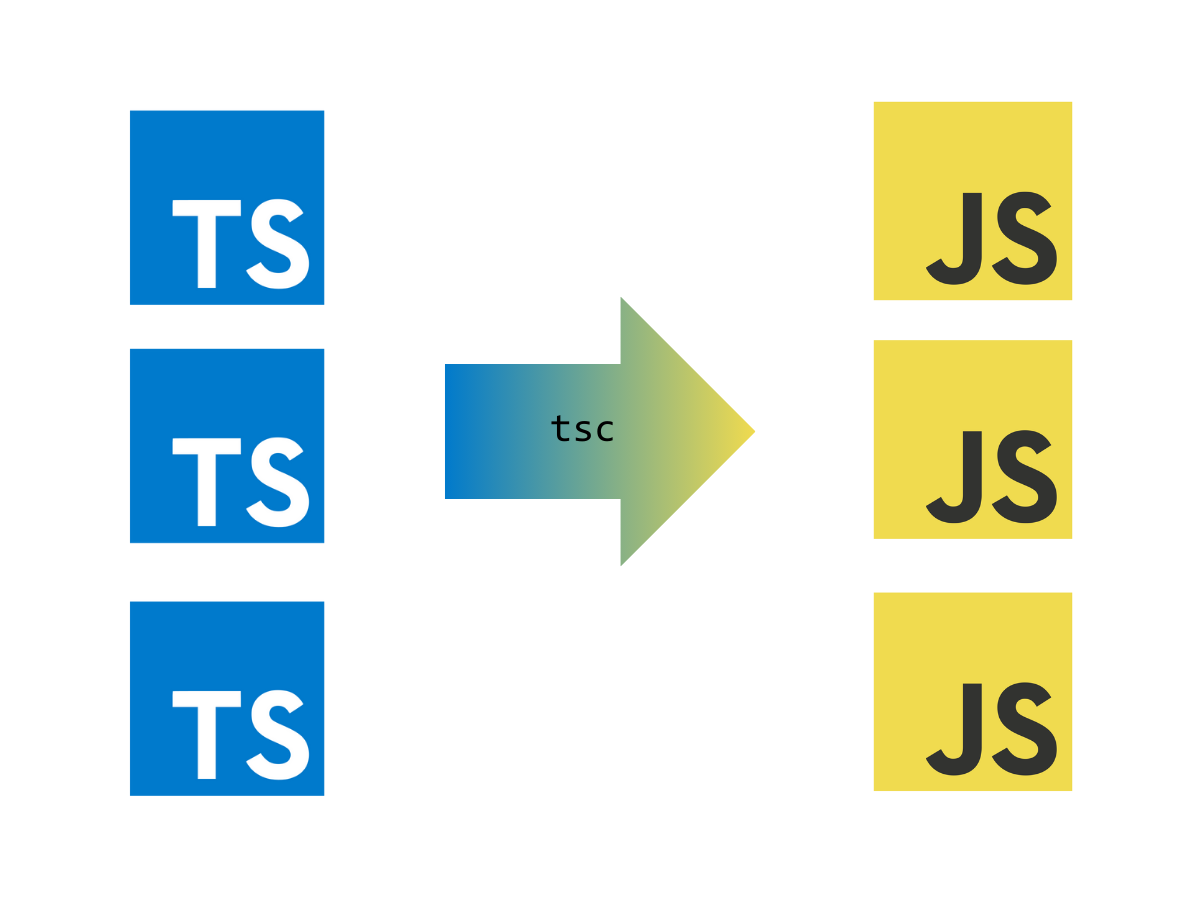
As a frontend developer, one of the things you should know is how TypeScript compiler works. Sooner or later you will work with this language (which I sincerely wish you!), so it’s good to know your stuff 😉
In this article, I will explain TypeScript compiler to you in simple terms. We will avoid complex stuff – only what you need for your everyday frontend developer’s work. We will not explore the inner workings of the TypeScript compiler Instead, we’ll see some practical implications of its workings for TypeScript developer. Let’s dive in 🙂
If you asked me 5 years ago what a JavaScript bundler is, I’d probably tell you it’s something people fight with for hours, just to get a simple web app set up 🤪 While this might have been closer to the truth in 2018, a lot has changed in JavaScript ecosystem until today.
If you’re starting your web development journey, or maybe have already dived into it, but are not really sure what JS bundlers are and what’s their role, you’re reading a proper piece of explanation 🙂
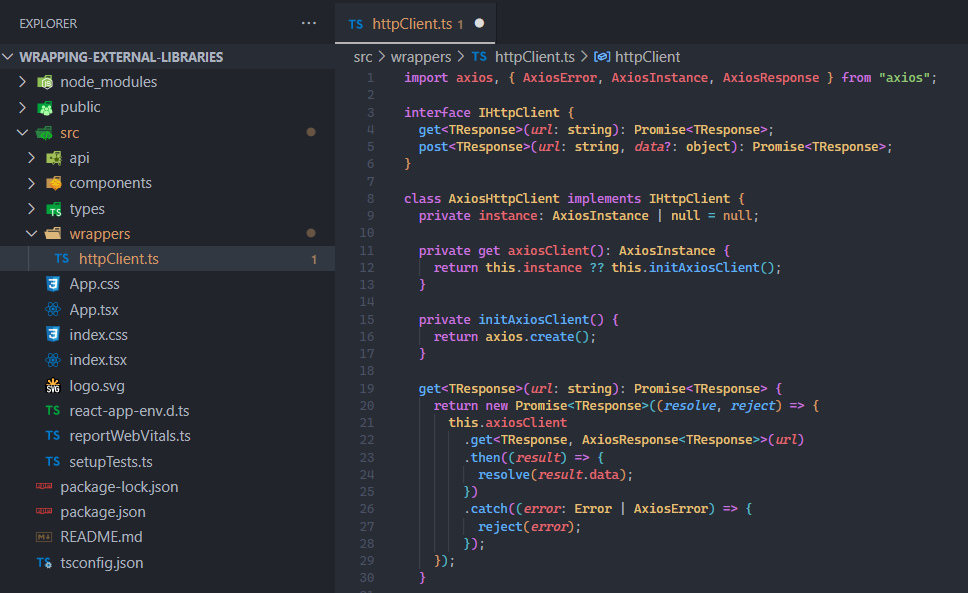
If you use external libraries in your application, wrapping them may be very helpful. How to wrap external libraries and why it’s worth doing that? Today we’re going to dive into that, based on a TypeScript web app example 😉
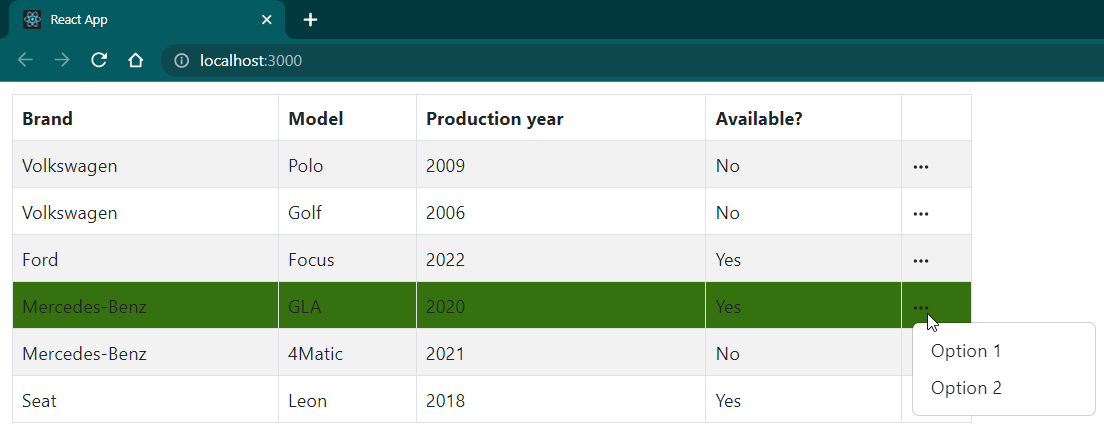
Meatballs menu (⋯), also called three horizontal dots menu, is a great way of providing contextual options for grid rows. In this article, I will show you how to add the meatballs menu to a table built with @tanstack/react-table.
After reading this article, you will know how to add such a menu to your React app. The end result will look as in the highlighted picture of this article 😉
I love VS Code 😍 There’s no better web code editor out there for me. Today, I’m going to share with you the 10 VS Code extensions that make my life easier. I can’t imagine coding without them. Let’s dive into it!
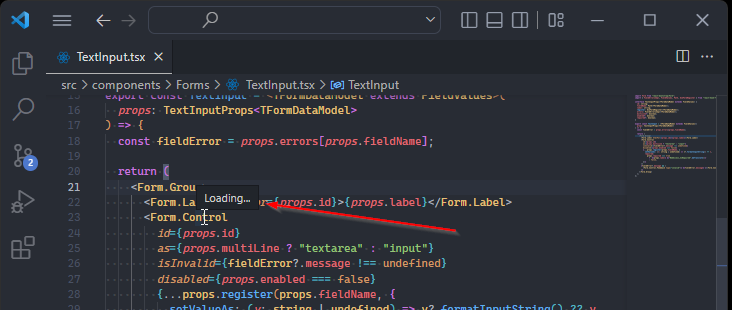
The symptoms of this issue are putting your mouse on something where you’d expect the IntelliSense guidelines, but instead you only see the “Loading…” text.
In this short article, I’m sharing the reason of this issue and my way of fixing it.
Have you ever needed to synchronize types in your frontend app with the backend API?
If you ever had an API action defined like that in your controller:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
and fetched this data using TypeScript in the following way:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
at some point, you probably also experienced the desynchronization of backend (C#, in our example) and frontend (TypeScript) types definitions. What if someone has changed the C# version of UserViewModel, but no one corrected its TypeScript’s equivalent?
Your TypeScript fetching code will tell nothing about that. There will be no error, even though the fetched data doesn’t match the expected UserViewModel type.
I’ll try to address this issue in this article 🙂 Let’s see how typing API responses with zod can help us here.
I recently needed to write test progress to the console with NUnit. The task we want to solve here is basically the TODO part of this snippet:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
As most websites, this blog uses cookies. This is to make using the blog comfortable 🙂 Staying on this website, you accept the usage of cookies.OKMore info